
611. Как нейросеть MinD-Vis преобразует активность мозга в изображение

Расшифровка визуальной информации из активности мозга — это способ узнать больше о том, как работает зрительная система человека, и как заложить основу для создания системы, в которой люди и компьютеры могут общаться друг с другом с помощью сигналов мозга. Однако создать чёткие и точные изображения из записей мозга может быть сложно, потому что сигналы мозга сложны и часто не хватает данных для должного обучения.
Человеческое восприятие определяется как свойствами объективных стимулов, так и прошлым опытом, которые вместе формируют сложную мозговую деятельность. Цель когнитивной неврологии состоит в том, чтобы понять эту мозговую деятельность. Декодирование визуальной информации из активности мозга — одна из сложных проблем, на которой сосредоточена когнитивная неврология. ФМРТ обычно используется для косвенного измерения мозговой активности, и уже несколько лет исследователи пытаются использовать нейросети, чтобы попытаться напрямую восстановить визуальные стимулы из ФМРТ. Однако это сложно, поскольку восстановленные изображения обычно размыты и бессмысленны. Крайне важно изучить эффективные и биологически обоснованные представления для ФМРТ, чтобы можно было установить чёткую и обобщаемую связь между деятельностью мозга и визуальной информацией. Индивидуальность мозга каждого человека ещё больше усложняет эту проблему.

Сравнение реальных данных(GT) c результатами разных моделей генерации. В этой статье мы рассматриваем модель, результаты которой обведены в красный
▍ Как работает MinD-Vis
Сначала изучается эффективное представление данных фМРТ с использованием автоэнкодера. Затем, дополняя модель Latent Diffusion, кондиционированием представления фМРТ, модель способна реконструировать весьма правдоподобные изображения с семантически совпадающими деталями из записей мозга.
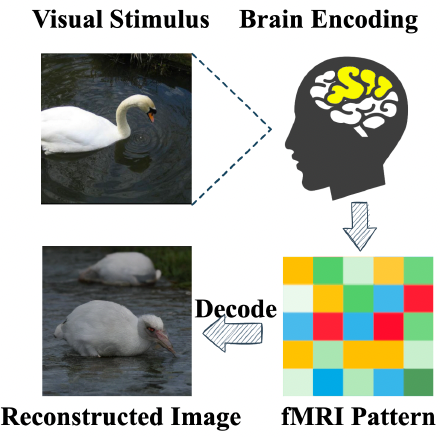
▍ fMRI и его преобразование
МРТ, измеряющая сигналы BOLD, является косвенной и агрегированной мерой активности нейронов, которая может быть проанализирована иерархически с помощью функциональных сетей. Функциональные сети, состоящие из вокселей данных ФМРТ, имеют неявные корреляции друг с другом в ответ на внешние стимулы. Следовательно, изучение этих неявных корреляций путём восстановления замаскированных вокселей, обеспечит предварительно обученную модель глубоким контекстуальным пониманием данных ФМРТ.
Мозг кодирует визуальную информацию скудно, что означает, что большинство естественных изображений активируют лишь небольшую часть нейронов в зрительной коре. Это повышает эффективность передачи информации и создаёт минимальную избыточность в мозге.
Визуальная информация может быть восстановлена из небольшой части данных, собранных из первичной зрительной коры с помощью различных методов визуализации, включая ФМРТ.
Авторы предлагают делить векторизованные воксели фМРТ на заданные участки и в последствии передавать их в одномерный автоэнкодер.
В статье использовали размер патча 16, размер встраивания 1024, глубину кодирования 24 и коэффициент маскировки 0,75 в качестве полной настройки модели с предварительно обученной Latent Diffusion.
Сжатое представление мозговой активности теперь можно передавать в Latent Diffusion для восстановления его в изображение.
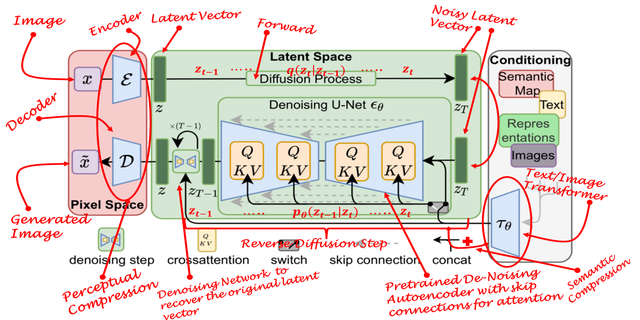
▍ Latent Diffusion
Модель скрытой диффузии состоит из двух компонентов: автокодеров с регуляризацией векторного квантования и модели шумоподавления на основе UNet с модулями внимания. Автоэнкодер с регуляризацией векторного квантования сжимает изображения в скрытые объекты меньшей размерности, а модель шумоподавления на основе UNet с модулями внимания позволяет гибко настраивать генерацию изображений с помощью векторов key/value/query (о которых подробнее я рассказывал в этой статье) во время переходов по цепочке Маркова.
Авторы статьи сделали файнтюн модели Latent Diffusion с кондиционированием, обучая модель на сжатых данных фМРТ мз прошлого блока.
▍ Код
Для большинства подобных статей код не выкладывают, но в нашем случае страничка на github обзавелась не только кодом, но и инструкциями по обучению!
С полным кодом вы можете ознакомиться здесь.
Немного кода файнтюна маскированного автоэнкодера (MAE):
Функция main() является основной функцией скрипта stageA2_mbm_finetune.py. В ней происходит инициализация нейронной сети и загрузка предобученных весов. Далее происходит создание объекта класса DataLoader, который отвечает за разбиение данных на батчи и итерацию по ним при обучении.
# create model
num_voxels = (sd['model']['pos_embed'].shape[1] - 1)* config_pretrain.patch_size
model = MAEforFMRI(num_voxels=num_voxels, patch_size=config_pretrain.patch_size, embed_dim=config_pretrain.embed_dim,
decoder_embed_dim=config_pretrain.decoder_embed_dim, depth=config_pretrain.depth,
num_heads=config_pretrain.num_heads, decoder_num_heads=config_pretrain.decoder_num_heads,
mlp_ratio=config_pretrain.mlp_ratio, focus_range=None, use_nature_img_loss=False)
model.load_state_dict(sd['model'], strict=False)
model.to(device)
model_without_ddp = model
# create dataset and dataloader
if config.dataset == 'GOD':
_, test_set = create_Kamitani_dataset(path=config.kam_path, patch_size=config_pretrain.patch_size,
subjects=config.kam_subs, fmri_transform=torch.FloatTensor, include_nonavg_test=config.include_nonavg_test)
elif config.dataset == 'BOLD5000':
_, test_set = create_BOLD5000_dataset(path=config.bold5000_path, patch_size=config_pretrain.patch_size,
fmri_transform=torch.FloatTensor, subjects=config.bold5000_subs, include_nonavg_test=config.include_nonavg_test)
else:
raise NotImplementedError
print(test_set.fmri.shape)
if test_set.fmri.shape[-1] < num_voxels:
test_set.fmri = np.pad(test_set.fmri, ((0,0), (0, num_voxels - test_set.fmri.shape[-1])), 'wrap')
else:
test_set.fmri = test_set.fmri[:, :num_voxels]
print(f'Dataset size: {len(test_set)}')
sampler = torch.utils.data.DistributedSampler(test_set) if torch.cuda.device_count() > 1 else torch.utils.data.RandomSampler(test_set)
dataloader_hcp = DataLoader(test_set, batch_size=config.batch_size, sampler=sampler)
Пара моментов из файнтюна Latent Diffusion:
Функция to_image принимает массив изображений в качестве входных данных и преобразует его в изображение PIL. Функция channel_last переупорядочивает каналы изображения таким образом, чтобы последнее измерение представляло каналы.
def to_image(img):
if img.shape[-1] != 3:
img = rearrange(img, 'c h w -> h w c')
img = 255. * img
return Image.fromarray(img.astype(np.uint8))
def channel_last(img):
if img.shape[-1] == 3:
return img
return rearrange(img, 'c h w -> h w c')
Функция finetune обучает модель на заданных обучающих и тестовых наборах данных. Он использует PyTorch Lightning Trainer для обучения модели в течение заданного количества эпох.
Функция get_args_parser создаёт анализатор аргументов для анализа аргументов командной строки. Он определяет несколько аргументов, связанных с проектом и обучением модели, включая пути к данным и предварительно обученным моделям, размер пакета и скорость обучения, а также количество эпох.
Функция update_config обновляет конфигурацию модели, устанавливая атрибуты объекта конфигурации в значения соответствующих аргументов командной строки.
Функция create_trainer создаёт PyTorch Lightning Trainer с указанными настройками. Он устанавливает ускоритель на GPU, если GPU доступен, и устанавливает максимальное количество эпох для обучения, точность и количество пакетов накопления градиента. Он также устанавливает значение отсечения градиента и включает контрольные точки со сводкой модели.
# finetune the model
trainer = create_trainer(config.num_epoch, config.precision, config.accumulate_grad, logger, check_val_every_n_epoch=5)
generative_model.finetune(trainer, fmri_latents_dataset_train, fmri_latents_dataset_test,
config.batch_size, config.lr, config.output_path, config=config)
# generate images
# generate limited train images and generate images for subjects seperately
generate_images(generative_model, fmri_latents_dataset_train, fmri_latents_dataset_test, config)
return
def get_args_parser():
parser = argparse.ArgumentParser('Double Conditioning LDM Finetuning', add_help=False)
# project parameters
parser.add_argument('--seed', type=int)
parser.add_argument('--root_path', type=str)
parser.add_argument('--kam_path', type=str)
parser.add_argument('--bold5000_path', type=str)
parser.add_argument('--pretrain_mbm_path', type=str)
parser.add_argument('--crop_ratio', type=float)
parser.add_argument('--dataset', type=str)
# finetune parameters
parser.add_argument('--batch_size', type=int)
parser.add_argument('--lr', type=float)
parser.add_argument('--num_epoch', type=int)
parser.add_argument('--precision', type=int)
parser.add_argument('--accumulate_grad', type=int)
parser.add_argument('--global_pool', type=bool)
# diffusion sampling parameters
parser.add_argument('--pretrain_gm_path', type=str)
parser.add_argument('--num_samples', type=int)
parser.add_argument('--ddim_steps', type=int)
parser.add_argument('--use_time_cond', type=bool)
parser.add_argument('--eval_avg', type=bool)
# # distributed training parameters
# parser.add_argument('--local_rank', type=int)
return parser
def update_config(args, config):
for attr in config.__dict__:
if hasattr(args, attr):
if getattr(args, attr) != None:
setattr(config, attr, getattr(args, attr))
return config
def create_readme(config, path):
print(config.__dict__)
with open(os.path.join(path, 'README.md'), 'w+') as f:
print(config.__dict__, file=f)
def create_trainer(num_epoch, precision=32, accumulate_grad_batches=2,logger=None,check_val_every_n_epoch=0):
acc = 'gpu' if torch.cuda.is_available() else 'cpu'
return pl.Trainer(accelerator=acc, max_epochs=num_epoch, logger=logger,
precision=precision, accumulate_grad_batches=accumulate_grad_batches,
enable_checkpointing=False, enable_model_summary=False, gradient_clip_val=0.5,
check_val_every_n_epoch=check_val_every_n_epoch)▍ Итоги

Это очень важное для науки исследование на стыке нейробиологии и машинного обучения. Не дадут ли нам в конечном итоге искусственные нейронные сети понять наши? Куда это пойдёт дальше и сможем ли мы это использовать в медицинских целях? Следить за новыми технологиями для изучения работы человеческого мозга очень интересно и сегодня вы познакомились с одной из них.
Данная статья частично была написана нейросетью ChatGPT.